最近在慕课网上学习了一门python爬虫课程《Python开发简单爬虫》,并利用课程中学到的知识自己编写了一个豆瓣相册爬虫,可以一键快速下载豆瓣相册中的图片,并且会自动下载大图。
在这里将这个爬虫分享出来,因为网络上的豆瓣相册下载器基本上都不能使用了,所以才想到自己开发一个,方便大家使用。
一、程序代码
github: https://github.com/xinxingli/douban_spider
本地下载:
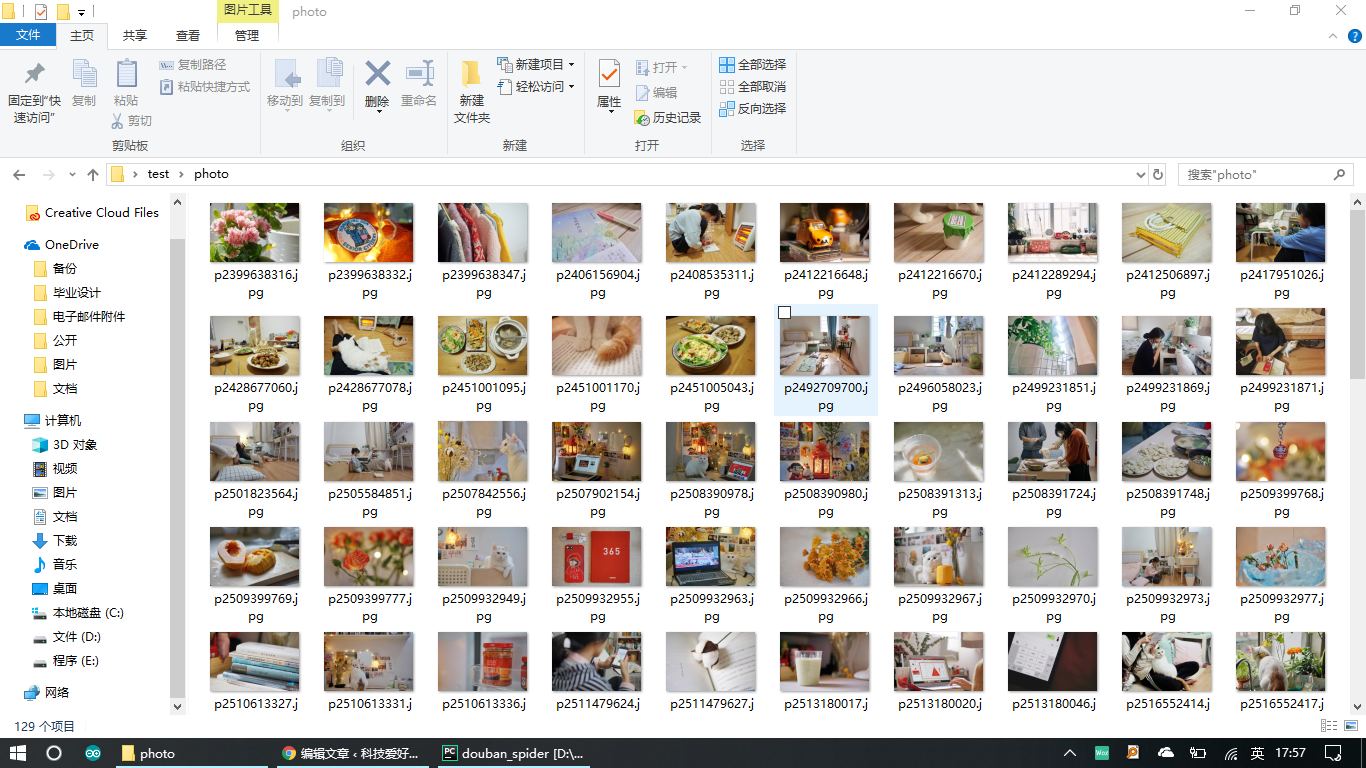
二、爬虫运行截图


三、主要程序代码
调度程序 spider_main.py
from douban_spider import url_manger
from douban_spider import html_downloader
from douban_spider import html_parser
from douban_spider import html_outputer
class SpiderMain(object):
def __init__(self):
self.urls = url_manger.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self, root_url):
count = 1
self.urls.add_new_url(root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print('爬取第 %d 页: %s' %(count, new_url))
html_cont = self.downloader.download(new_url)
new_urls, new_data = self.parser.parse(new_url, html_cont)
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
if count == 10:
break
count = count + 1
except:
print('craw failed')
self.outputer.output_html()
if __name__ == '__main__':
str = input("请输入要下载的豆瓣相册ID(例如1639309626): ")
root_url = 'https://www.douban.com/photos/album/'+str+'/'
print('即将开始下载相册: %s ' % root_url)
obj_spider = SpiderMain()
obj_spider.craw(root_url)
网址管理程序 url_manger.py :
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
def has_new_url(self):
return len(self.new_urls) != 0
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
网页下载程序 html_downloader.py :
#from urllib import request
import urllib.request
class HtmlDownloader(object):
def download(self,url):
if url is None:
return None
response = urllib.request.urlopen(url)
if response.getcode() != 200:
return None
return response.read()
解析程序html_parser.py :
from bs4 import BeautifulSoup
import re
import urllib.parse
import urllib.request
class HtmlParser(object):
def _get_new_urls(self,page_url,soup):
new_urls = set()
links = soup.find_all('img',width="201")
for link in links:
photo_url = link['src']
photo_url_list = list(photo_url)
photo_url_list[37] = 'l'
photo_url = ''.join(photo_url_list)
photo_name = photo_url[46:57] #取出连接中的图片名称
print('正在下载图片:%s.jpg'% photo_name)
urllib.request.urlretrieve(photo_url, 'photo/%s.jpg' % photo_name)
pages = soup.find_all('a', href=re.compile(r'https://www.douban.com/photos/album/\w*/\?start'))
for link in pages:
new_url = link['href']
new_full_url = urllib.parse.urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self,page_url,soup):
res_data={}
res_data['url'] = page_url
return res_data
def parse(self,page_url,html_cont):
if page_url is None or len(html_cont)==0 :
return None
soup = BeautifulSoup(html_cont,'html.parser',from_encoding='iso-8859-1')
#from_encoding='iso-8859-1'
new_urls = self._get_new_urls(page_url,soup)
new_data = self._get_new_data(page_url,soup)
return new_urls,new_data
输出程序 html_outputer.py :
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
def output_html(self):
fout = open('output.html', 'w', encoding="utf-8")
fout.write("<html>")
fout.write("<head><meta http-equiv=\"content-type\" content=\"text/html;charset=utf-8\"></head>")
fout.write("<body>")
fout.write("<table>")
for data in self.datas:
fout.write("<tr>")
fout.write("<img ")
fout.write("width=\"201\" src=%s />"% data['url'] )
fout.write("</tr>")
fout.write("</table>")
fout.write("</body>")
fout.write("</html>")
fout.close()